
Almost every methodological approach in software development aims to reduce development time and produce more qualified products. Continuous Integration (CI) also aims to reduce development time. Basically, CI is software development practice that developers need to check-out their codes in their local development environment and than integrate them to shared repository. According to Martin Fowler who known by his studies about CI, there should be at least one integration to shared repository done everyday, but the frequency of integration is expected to be more than one integration. By this way, test activities are performed during every integration and problems caused by the integration can be minimized. As it is emphasized in this blog, CI says us as "pay me now, or pay me more later". If we look at the history of CI, it goes back to extreme programming (XP) which advocates that there should be frequently code merged to master to cover unstable requirements of customers. CI was applied as a part of XP by merging local codes to shared code and than test it and than develop for next integration and this cycle should be performed everyday. Therefore CI is very effective practice for iterative software development.
Application of Continuous Integration
As I tried to explain to apply the CI practices developers get the latest code base from shared repository than add their new codes and than merged them to the shared repository again. This process should be performed several time in a day. In this procedure, testing should be automated and manual testing can be also performed after new codes release to source code. If any failure is detected by integration server or test environment, it should be reported to related people and they fixed it and merged to new code into the CI again. As we know that the latest code causes this bug and after the "good code" works well. Therefore, efficiency of CI can be seen by this way as it is said to be "fix your bug early and often". The below picture show the philosophy of CI in basic for general software development methodology.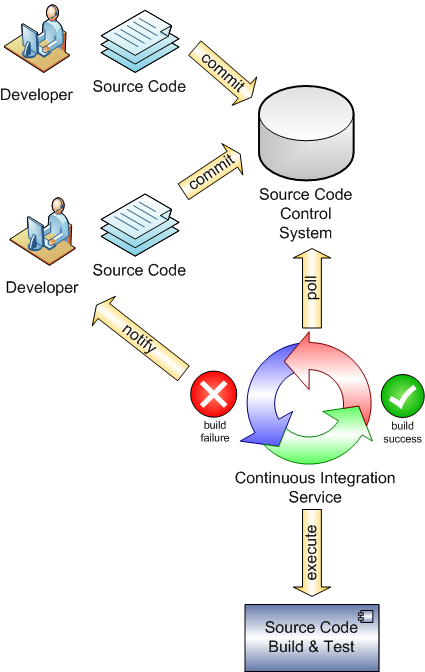 |
| Application of Continuous Integration |
- As in the picture, in middle of the process there is a source code control system which controls the code when the developers push their code into source code. Than continuous integration checks the system if there is anything wrong with that is not in "good code". If any any bug find in the source code it send failure notification to developers (actually if error occur, everyone should know it). If the CI doesn't report error about integration, the new "good code" is taken into source code test environment for regression and advance testing. However this explanation doesn't reflect everything for agile which is very popular software development methodology. Let's look at the process which is drawn by Rational for agile and test driven development.
 |
| CI for Agile and Test Driven Development |
For agile development, there are product backlog and sprint to develop the product step by step belonging to the iterative approach. As seen for TDD, unit tests are written first than product code should be written until all the test are passed. Steps like this:
- For the sprint, take the requirements
- Write unit tests
- Develop product code until every test case are passed
- Run unit tests
- Merge new code into shared repository
- CI, integration test and regression testing
- If any error, report it quickly; If no error, merge new code to product
- Next sprint starts
Advantages of Continuous Integration
- Risk are reduced
- Bug can be found and reported quickly
- Project visibility is increase
- Keeping development branch updated is easier
- Reduce number of regression test
- Product for test is ready every time
- Enforce you to have better development process
Disadvantages of Continuous Integration
- There should be additional tools such CI, Test. List of tools click here
- There should change in development mindset
- Required more discipline
- Refactoring may be difficult because of unstable code base